Data structures to support standard error calculations for direct adjustment assisted by a prior covariance model
Ben Hansen
April 2022 (+ subsequent non-substantive updates)
Source:vignettes/sandwich_infrastructure.Rmd
sandwich_infrastructure.RmdContext
The user has specified a comparative study design and separately fitted a covariance model. E.g.:
des <- obs_design(treat ~ strata(district) + cluster(school, classroom),
data =Q_)
cmod <- glm(promotion ~ pretest + gender,
family=binomial(), data = C)The data frames C and Q_ describe the
covariance and quasiexperimental samples, potentially at different
levels of aggregation. For instance C might give student
data while Q_ is a table of classrooms. The samples they
describe may be disjoint, identical or overlapping.
Next she uses lm() (or propertee’s
lm()-wrapper, lmitt()) to calculate directly
adjusted1
estimates of an intention-to-treat effect:
m <- lm(promotion ~ treat * gender, data = Q,
offset = cov_adj(cmod),
weights = ate(des))
coef(m) # spits out effect estimateswhere Q may be the same as Q_, or
Q_ may describe aggregates of units described in
Q; the offset is similar to what
predict(cmod, newdata=Q, type="response") would have given;
and the weights are of the Horwitz-Thompson, inverse probability of
assignment type.
At this point m has class lm, but with
additional information tucked away in m[['model']]: this
data frame will have special columns (weights) and
offset(cov_adj(cmod)). The propertee
package implements an S4 class WeightedDesign that extends
the base numeric vector type and encodes information beyond unit weights
necessary for standard error calculations, and arranges that
m[['model']][['(weights)']] is of this type. This note
describes two classes appropriate for
m[['model']][['offset(cov_adj(cmod))']]:
SandwichLayer, and a fallback option
PreSandwichLayer, for use when the call to
cov_adj() producing this object is able to locate some but
not all of the necessary information.
Standard errors will be obtained through subsequent steps, e.g.
or
with “uoa1” and “uoa2” the column names of
clusters(des), while altuoa1 and
altuoa2 corresponding column names of C,
or
where keys_data_frame has rows aligned with those of
C and columns including “uoa1” and
“uoa2”.
Either way, once m has been coerced to class
teeMod, it has acquired a @Design slot for the
information in des, while m[['model']] will
have a column offset(cov_adj(cmod)) of class
SandwichLayer. Together these objects will contain the
necessary additional information to perform standard error calculations
that:
- attend to the structure of the design, as recorded in
des; and - propagate errors from the fitting of covariance model
cmodinto standard errors reported fortreat * gendercoefficients.
Formal class structure proposal
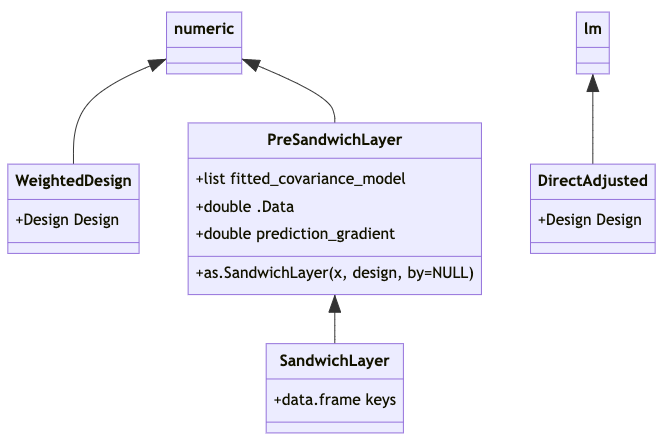
Like the existing class WeightedDesign, the
PreSandwichLayer and SandwichLayer classes
extend the base numeric vector type, with numeric vectors (of
predictions) in their @.Data slots.
PreSandwichLayer and SandwichLayer also have a
@prediction_gradient slot, for a numeric matrix of
dimension
Regarding as.SandwichLayer(): Turning a
PreSandwichLayer, x, into a
SandwichLayer amounts to providing a mapping from the rows
of model.matrix(x) or sandwich::estfun(x) to
units of assignment recorded in des. This mapping is to be
recorded in the @keys data frame, which has as many rows as
model.matrix(x) and columns storing unit-of-assignment
(clustering) information as well as a Boolean variable indicating
whether such unit of assignments could be found in des.
The mapping can be effected via
expand.model.frame(x, vars, <...>). If
by=NULL, then vars is the vector of names of
unit-of-assignment variables given in the design,
desvars say. Otherwise by is a named character
vector giving a crosswalk, the second argument to
expand.model.frame() should be by[desvars],
and those names should be switched out of column names inthe data frame
expand.model.frame() returns in favor of
desvars.
In order for vcov.teeMod(m) to work, the following
functions must have methods applicable to
m@fitted_covariance_model: model.matrix(),
sandwich::estfun(), sandwich::bread(). These
are similar requirements to those of
sandwich::vcovHC().
Basis in known extensions of Huber-White setup to chained estimators
With reference to the formulas for stacked estimating equations of
Carroll, Ruppert, Stefanski and Crainiceanu (2006, p.373), the
covariance model has psi functions (estimating equations)
with parameters
,
and Fisher information and estimating-equation covariance matrices
and
respectively; while the direct adjustment model’s are
,
the treat coefficients being
,
with sandwich components
and
.
(The symbols
“”,
“”
and
“”
are used as Carroll et al use them, while our
“”
corresponds to their
script-.)
We take to range over the units of assignment (clusters) not elements2. The Carroll et al development is missing factors at the right of the equations defining . To avoid ambiguities in mapping to external subroutines’ understanding of “”3, let’s address the error by leaving those displays as-is, while striking the leading factors from display (A.34) and from the subsequent expression for : i.e., turn the A and B matrices into sums not means. Carroll et al’s formulas for , and then apply, although design-based standard errors call for different calculations of , and . (When we get around to putting the multidecker sandwich together, we’ll need to be cognizant of the fact that its As and Bs are means not sums, and ready to compensate for the fact that it will have divided by different in figuring the means that are and , for example.) Denote the clusters/units of assignment that are represented in covariance and quasiexperimental samples by and respectively.
Required materials for SE calculations
To estimate variances and covariances of , we’ll need to assemble the following materials.
- Sufficient information about and to identify their intersection , as is needed to estimate ;
- Matrices of estimating functions and , as are needed for ;
- For the quasiexperimental sample , matrices corresponding to , where “” means “elements of cluster ” and “” is interpreted to mean “” if there is no clustering;
- Estimates of the direct adjustment model’s “bread matrix” , i.e. the inverse of its Fisher information w.r.t. only, along with the “meat matrix” ;
- The covariance model’s bread matrix ; and
- for covariance estimation in the conventional “model-based” setup only, estimates of the covariance model’s B matrix (a “clustered” covariance estimate).
In (5), observed information is preferred to “observed expected” information, , because observed information is agnostic as to whether expectation is calculated with conditioning on potential outcomes, ie the finite population perspective, or with conditioning on treatment assignment, the model based perspective. In the special case of quantile regression4, observed information isn’t ordinarily used in standard error calculations, and it may take some doing to get.
Regarding (6), is not needed for design-based standard errors, as in this setting observations outside of the quasiexperimental sample do not contribute to the covariance model’s B matrix. Only quasiexperimental sample observations do, and we’ll have access to these when the direct adjustment model is fit. As we also have and , we can use these materials to estimate and .
Software implementation comments on 1–6 above, including contents of
{Sandwich/Vegan}{Layer/LayerKit}
objects
1. A SandwichLayer object s_l_o carries a
keys data frame with which to identify rows of
model.matrix(s_l_o) with units of assignment (as named in a
separate Design object). The association can be many-one (but not
one-many); it is not required that named units appear in the design. As
covmod itself won’t be aware of these cluster associations,
assembling this info at runtime calls for trickery, as well as a means
for users to override the trickery and directly provide key variables
that the design will need. A falsy value in the in_Q column
of keys indicates an observation not appearing in the
Design object.
2. Estimating functions may need to be aggregated (summed) to the cluster level before calculation of . There should be a dedicated function to calculate from the cluster-aggregated estimating function matrices.
3. PreSandwichLayer and SandwichLayer have
an @prediction_gradient slot for a numeric matrix. This
matrix has as many rows as there are entries in the .Data
vector, and as many columns as there are estimating equations.
The @prediction_gradient slot carries
,
where
ranges over rows of Q as above – elements not clusters
where the distinction exists – and
represents the prediction for data
from a fitted model of class(cov_mod) with parameters
.
For
’s
that use only “predictions” of the covariance model, as ours does, the
first derivative of the covariance model predictions as applied to data
in
will provide sufficient information from the covariance model to
complete the calculation of
.
For glm and similarly typed objects cmod,
such predictions are a joint function of family(cmod) and
the model.matrix generated in the process of creating
predictions from cmod.
4. The SandwichLayer class isn’t implicated in (4). We
can take extant calculations of a direct adjustment model’s information
matrix, with the proviso that we keep track of whatever scaling those
calculations may have applied. For design-based SEs we’ll need our own B
matrix calculation. For model-based SEs we can plug in to extant
routines for
also, but being careful ensure clustering on the units of assignment (as
named in a Design object). Scaling of these matrices should default to
the conventions of the sandwich package. (I haven’t considered whether
use of HC0–3 etc for
calls for corresponding adjustment to estimation of
and/or
,
nor whether heuristics animating these adjustments make sense in this
context.)
5. sandwich::bread() will be used to retrieve
.
We can take extant calculations of a covariance model’s information matrix, defaulting to scaling conventions implemented in the sandwich package.
6. sandwich::meatCL() will be used to retrieve
.
For now we only try to implement HC0 & HC1. (I haven’t considered
whether use of HC0–3 etc for
calls for corresponding adjustment to estimation of
and/or
,
nor whether heuristics animating these adjustments make sense in this
context.)